To close out this year, I want to talk about why I am doing the Subspace experiment and where I see it going. The ultimate goal is memory safety in C++, which has become quite the hot topic in the last few months.
This post ended up referring quite a lot to cor3ntin’s fantastic recent post on C++ safety. I agree with a lot of it, and disagree with some of it, and I recommend reading that first if you haven’t!
This is a long post, so here’s a table of contents if you’d like to jump around. To understand Subspace where is going, I believe it’s helpful to also understand how it began, and what else was tried first. So let’s start there.
(Disclaimer: This post is full of opinions, 100% of which are mine and do not represent my employer, my colleagues or possibly anyone else.)
- The land before space-time
- Starting principles
- How to change C++
- Starting Subspace
- Where does Subspace go next
- The future
- Other recent work
The land before space-time
I started the Subspace experiment on May 6, 2022. Well, that was the first commit, however I actually started this experiment in 2021. The Chromium project was seeing an ever increasing number of memory safety bugs in C++ and was looking for answers.
- Rust had been proposed in the previous year as a way forward but was turned down in the summer of 2020, with the conclusion “we don’t recommend proceeding with the proposal at this time”.
- MiraclePtr was being iterated on, and it was both unclear if it would make it to production, and clear it was not a complete answer to all memory safety problems or use-after-frees in C++.
- Chrome Security was enumerating Undefined Behaviour in C++ and documenting what was being done so far. It told the story of a thousand plugs trying to stop a ship from sinking. But there was no coherent overarching story behind it all, and many issues had no clear way to resolve them. This continues today on a one-by-one basis.
So at the start of 2021, I was given the small task of “figure out memory safety for Chromium”, and off I went.
My first study was of what minimal changes would be required in the C++ language to get guarantees of lifetime safety at runtime for all stack and heap objects. I called this work “Boring Pointers” in the spirit of BoringSSL, and I should work to put this into the public domain. I had no experience working with WG21, nor awareness of how things worked at the C++ committee level. However, I came to learn that while the changes to the language were somewhat small, they were much less realistic than I may have hoped. Maybe things have changed a little since then: the committee is at least talking about safety, and CppCon22’s closing keynote included a strong desire for memory safety in C++.
My next stop was to consider what the lessons of Rust may be that we could take back to C++. Could C++ have a borrow checker? Another colleague, @adetaylor, had considered a runtime borrow checker briefly. Runtime-only safety checks push the feedback cycle on bugs really far from the development process, sometimes right out into the shipped release. This makes sense for defense in depth, but it does not resonate for me as a strategy for developers to rely on. I explored if we could do borrow checking in the C++ type system, through something like smart pointers. Ultimately, no.
Another key lesson from Rust is found in its integer types. Clean APIs for handling trapping, wrapping, and saturated arithmetic. No conversions you didn’t ask for, especially conversions that involve gaining or losing a sign bit, or truncating your value. Trying to fix integer unsafety in C++ while working with primitive C++ types has presented itself as nearly impossible. Chromium has safe integer types and casts, which was a great innovation by @jschuh. Rusts integer types take this idea and make it extremely ergonomic. A colleague in Chrome Security, @noncombatant, was exploring the idea of a standard-library-like project, which we called libboring after Boring Pointers. This encoded the idea to provide safe arithmetic in a library for projects like Chromium to consume, while giving some space to rethink the API. However it didn’t gain a lot of traction immediately, it would need a significant engineering investment, and there were other things to explore still.
So I steered toward considering if Chromium could use Rust to move toward memory safety. It had been rejected once before, but there was so much more to learn. The question that needed answering was how to fit Rust into the Chromium project in a way that would make sense to developers, be easy to use, and have a story for how use of Rust would change over time, with incremental adoption. Rust would need to replace C++ code as a primary language over time, all through the software stack, if it was going to solve the memory safety problems in C++.
My team was successful in finding good answers to a number of problems:
- Deterministic debug builds.
- Writing tests in Rust that integrate into our C++ Gtest framework. Though it did require some trips through Rust compiler bugs with static initializers, and exploring but ultimately rejecting a proposed RFC for custom test frameworks.
- Considering how to integrate async Rust into Chromium’s async Callback system.
But the Rust train hit a bit of a brick wall when we started looking carefully at unsafe Rust and aliasing rules. I had the fear of unsafe Rust instilled in me through my work on a side-project with @quisquous, developing a Rust wrapper around a C API for Playdate. It was far easier to introduce UB than I had imagined, and more importantly, far harder to find all the places that did so. Miri was no help for a project with language interop.
But worse (for Chromium) than introducing UB through unsafe Rust, we noticed that it’s trivial for C/C++ to introduce UB in Rust:
- Pass or return pointers that get held as Rust references and which alias illegally.
- Mutate anything that Rust has a reference to. This is especially easy since const is not transitive in C++ the way it is in Rust.
- All the familiar C++ use-after-free problems which it could leak into Rust.
This presented a new mental model for me that C++ is all unsafe Rust, which I am starting to see elsewhere, and which I found unsettling. No one would ever write 17M lines of unsafe Rust (the amount of C++ in Chromium), all interacting with each other freely in complex ways, and expect anything good to happen. This had an outsized impact on the shape of the nascent adoption of Rust in Chromium that was announced a month ago.
The Crubit project is heroically attempting to find ways to eliminate or contain the ways for C++ to introduce UB in Rust. I contribute to this project and I hope that it can succeed. But it’s also an experiment, and it’s not yet clear if the result will be ergonomic or simple enough to justify working with it as a primary development language.
If you’re writing something new, Rust is in my opinion the obvious choice over C++ in most scenarios. After the on-ramp, you will be more productive, especially when it comes time to refactor your code to add some new feature.
But we urgently need something to address the huge amount of existing C++ in Chromium, and elsewhere.
And so we must contend with the gloomy reality that is backward compatibility. Or rather, existing code.
Of all the C++ code written these past 40 years, a fair amount probably still runs. And the Vasa is no ship of Theseus. It would be, to my dismay, naive to imagine that all of that production code qualifies as modern C++. We should be so lucky to find reasonable C++ in consequential proportions. So, we should not expect guidelines about lifetimes and ownership to be followed.
– cor3ntin: https://cor3ntin.github.io/posts/safety/#a-cakewalk-and-eating-it-too
Starting principles
From this whole journey through C++ to Rust and back, I have acquired a few beliefs from which to work. And I see many of these same things being echoed around in recent days.
Rust did things right
A key belief that I have landed on, and have yet to be dissuaded of, is that Rust did things right. They had the benefit of hindsight over 40 years of development with C++, not to mention all the language research over that time. This led to the starting from the right principles, putting safety first and working from there.
The Rust standard library is well-designed, and provides a cohesive story of how to use the language and its features. This is in stark comparison to the C++ standard library which regularly gains new features (e.g. std::optional, concepts) but then fails to use those in its own design, presumably due to the committee’s commitment to backward compatibility with a library designed for C++98.
Work outside the establishment
If we’re going to find memory safety in C++, we need to look for ways outside the committee, and outside the compiler and standard library.
This has been further reinforced as the proliferation of “C++ successor languages” has rolled out this year from current and former WG21 members, including Carbon, Val, and Cpp2.
I find it a bit terrifying how the committee is sometimes willing to push things by 3 years, with little thought about how users would be impacted. If you look at concepts, coroutines, pattern matching, modules, and other medium-sized work, you are looking at a decade on average to standardize a watered down minimal viable proposal. However you look at it, shoving “safety” in the language sounds more complex than all of these things.
The idea is simple: instead of foaming at the mouth and shouting about memory safety, we should look at all checkable UB and precondition violations and assert on them… None of that requires changes to the core C++ language though. They are practical solutions that we could have deployed years ago. Luckily, most of these things don’t even need to involve the C++ committee.
– cor3ntin: https://cor3ntin.github.io/posts/safety/#but-we-care-about-safety-right
Make things better, but not worse too
Whatever solutions we consider can’t make things worse some of the time, even if it makes things better other times. This means not introducing new ways to have UB. C++ has enough already.
This is what makes Rust as a strategy to replace all C++ development in an existing project feel like a particularly risky endeavour. However, an endeavour that Crubit may enable in the future.
Incremental application is required
Any proposal for C++ memory safety must be able to be applied in an incremental manner across an arbitrarily complicated and interconnected codebase. This means it can be used for new code in an existing codebase, without disturbing existing code, but must still provide some tangible guarantees and benefits. And it must be able to be applied to existing code in an incremental way.
100% source compat, pay only when you use it.
– Herb Sutter on cpp2: https://www.youtube.com/watch?v=ELeZAKCN4tY
Leaving safety should be obvious
The default paths should be safe; developers should have to opt into unsafety
whenever possible. And doing so should be through a consistent and clear syntax
mechanism that can be seen clearly in code review, and can be watched for by
tooling. The unsafe keyword is the best example of this, but without the
ability to add keywords to the language, there must be another way.
- Pragma
unsafe_buffer_usageallow[s] you to annotate sections of code as opt-out of… the programming model…- Attribute
[[unsafe_buffer_usage]]lets you annotate custom functions as unsafe…– https://reviews.llvm.org/differential/changeset/?ref=3751471
Rust is not about having no dragons, it’s about containing them.
unsafealso raises red flags in code reviews, which is exactly what we want.– cor3ntin: https://cor3ntin.github.io/posts/safety/#borrowing-the-borrow-checker
Global knowledge is harmful
The Rust static analysis that produces memory safety is able to do so through local analysis of a single function at a time. This is the only approach that scales and can fit in developers heads. And by requiring functions to depend only on local knowledge, this also benefits developers. Humans are more likely to make mistakes if they have to understand state or requirements far from the code they are changing. New developers to a codebase will have to know that such things even exist to look out for.
New code is worth addressing
Changing how new code is written is meaningful. While most C++ code can be generally assumed to have memory safety bugs waiting to be found, new C++ code continues to be the largest observable source memory safety bugs in Chromium.
I like to think that most vulnerabilities in C++ have already been written. New code is more likely to abide by modern practices and use language and library facilities that make it easier to write correct code. Maybe. I am trying to be optimistic. Safety by good practices and convention certainly is no guarantee of anything but it does help, to a point.
– cor3ntin: https://cor3ntin.github.io/posts/safety/#a-cakewalk-and-eating-it-too
The reason memory bugs in new C++ code dominate is probably because fuzzers and researchers have already spent a lot of time on the existing code, making it unlikely for them to turn up new things there, even though they exist. But nonetheless this means relying on the current facilities of modern C++ to prevent memory safety bugs is not working as a strategy. We continue to write memory safety bugs as a software engineering industry at an incredible pace.
Interop with C++
The really big and really obvious takeaway here is: The easiest way to interop with existing C++ code is to stay in C++. Of course, then you have all the C++ memory safety problems, unless you’re working in a different C++.
One vision of a different C++ implies changes to the language itself, which leads to certain outcomes.
We can imagine adding non-aliasing references to C++. I am not sure exactly how. But it would go swimmingly though, exactly as it went with rvalue references. We also would have to figure out destructive move. We failed to do that once, but why should that stop anyone? So armed with our imaginary tools, we can start to have a nice and cozy “island of safety”. Our new safe code can call other safe code.
Surrounded by an army of raw pointer zombies, every time we would call or be called by the “unsafe subset of C++” (which would be 99.999% of C++ at that point), we risk the walls around our little safe haven to be toppled over.
…
So even if we could add a borrow checker to C++, would there be even a point? C++, is a “continent of unsafety”; by having a safe C++-ish language in C++, that dialect would look a bit foreign to most C++ devs, and it would integrate poorly, by design.
Sure, there are self-contained components that require more safety than others. For example, an authentication component, and a cryptography library.
We could use our safe dialect to write these.
…
We end up with a piece of code that does not look like the rest of our C++ nor integrate with it. At this point, could we have not written that piece of code in… Rust?
The rules of interaction between a hypothetical safe C++ and C++ would be no different than that of C++ and Rust through a foreign function interface.
“Rewrite it in a slightly different yet completely incompatible C++!” sure is a rallying cry!
– cor3ntin: https://cor3ntin.github.io/posts/safety/#borrowing-the-borrow-checker
If the “safe C++” is so different from normal C++, is a different language, you end up going through FFI anyways. But this is where Work outside the establishment comes in.
If we are constrained to working in C++ as it exists today, then the “safe C++” must integrate with existing C++. There must of course be some difference in how the safe C++ is constructed, or you have done nothing at all, but the impact of this difference on C++ beyond its borders is necessarily limited. Bugs or mistakes in the existing C++, the “army of raw pointer zombies” surrounding your “safe” code, may still introduce bugs in your code. But it can’t make things worse than they were before, there’s no new UB to be found by doing the wrong thing across the boundary. And other “safe” code would not be able to introduce memory bugs in your code. That would be something new to C++.
How to change C++
To primary way to change C++ without changing the language or the compiler is to write a library. The standard library exposes UB to the developer through many of its public APIs, and the committee will not remove those APIs.
The approach being taken in libc++ safe mode is to introduce asserts, and crash when UB would have occurred.
The idea is simple: instead of foaming at the mouth and shouting about memory safety, we should look at all checkable UB and precondition violations and assert on them. This is what I hoped for contract, the other C++ feature is highly related to the S-word and going nowhere.
– cor3ntin: https://cor3ntin.github.io/posts/safety/#correct-by-confusion
This provides defense in depth, it protects users against existing code, and is a good idea. But to be a safety strategy for C++ developers, we need to shift left. Instead of crashing on UB, I would like a future world where C++ developers have a different choice. A development environment which does not present a footgun at every turn. Define the UB out of existence.
We also need better tools to prevent UB from happening. In its arsenal, Rust offers saturating arithmetic, checked arithmetics (returning Optional), and wrapping arithmetics. I hope some of that comes to C++26. If you expect overflow to happen, deal with it before it does, not after.
None of that requires changes to the core C++ language though. They are practical solutions that we could have deployed years ago. Luckily, most of these things don’t even need to involve the C++ committee.
– cor3ntin: https://cor3ntin.github.io/posts/safety/#correct-by-confusion
Safe C++ code should not crash, it should be safe by construction. It should prevent the bugs from existing, not just try to prevent the bugs from being a backdoor onto your device. But that means safe C++ code can not depend on the standard library.
This presents a chicken-and-egg type of problem. Without safe C++, there’s no means to write a new standard library to satisfy the safe C++. Without a standard library there’s no way to have safe C++.
But the Rust community has done some seriously heavy lifting in this space. They have given us a language and an ecosystem of memory safe code, proving it is possible at scale, in production.
Rust understands the value of taking the resources to ensure the correctness of running programs. Correctness by default. Safety first. Even without a borrow checker, GCC’s Rust implementation is less sharp of a tool than C++.
They have a strong mental model for strong safety. They don’t throw exceptions in the presence of logic errors, with the naive hope that someone will handle that somehow, somewhere, and that the program should do something, anything to keep running.
And they do care about performance, undoubtedly. In many cases, Rust is as fast or faster than C++. And in very rare cases, the developer does know better than the compiler and there are escape hatches to unhook the safety harness, even if that comes with a lot of safety stickers in the documentation.
– cor3ntin: https://cor3ntin.github.io/posts/safety/#first-born-unicorn-dream-of-carcinization
The Rust standard library has no UB if you don’t drop down to unsafe. If we could expose a similar
demarcation in a C++ library, then users would not be exposed to UB unless they asked for it, and
their reviewers would be able to see where it was happening too. And the Rust standard library
goes further than just eliminating UB.
The Rust standard library presents a coherent system that builds on its own primitives (safe integers, Option, Result, etc).
We’ve seen Option and Result come to the C++ standard library, as optional and expected, but they both arrived with UB exposed through their C++ APIs, even just for consistency with pre-existing UB, and they are not used to make the C++ standard library easier to use correctly. Should safer integer types arrive in C++26 or 29 or 33, they will not appear in the APIs of the C++ standard library either.
Rust takes the position that defaults matter, and this is expressed throughout its standard library. Defaults like no null pointers. The best-in-class way to write a non-null pointer in C++ is somehow still a reference. But the C++ standard library does not treat references as such, and continues to introduce types that do not support the use of references in them.
Vobaculary types in Rust are composable and powerful with safe, rich APIs. For example the interactions between Option and Result, or Result and Iterators.
The APIs of the Rust standard library can be used in a world without mutable aliasing, a key component of locally enforced memory safety.
And being the excited library implementer that I am, I noted that the Rust standard library does some very nice things with type layout.
Starting Subspace
Subspace began from asking what it would look like to port the Rust standard library into C++20, for all the reasons elaborated above.
I began with PRINCIPLES.md
where I wrote my aspirations for the library. Much like Herb Sutter
with cpp2,
I desire to remove complexity from the language. And that hope is encoded in the
principles charter. Performance matters too, but slightly more important than just
performance is predictable performance. For example, the
small-string optimization
makes std::string faster in many cases, but it introduces a huge performance cliff that
is not visible to the user.
Then I moved on to implementation; the proof is in the pudding, as they say.
I started with integers, and Subspace now has integer and float types that provide the same safety guarantees (and APIs) as their Rust counterparts.
auto i = 2_i32; // An i32 type.
auto j = 2_u32; // A u32 type.
// Protects against sign conversion.
i += j; // Doesn't compile, it would require a sign conversion.
i += sus::into(j); // Converts `j` at runtime into an i32, terminating if the value won't fit.
// Protects against overflow.
j -= 10_u32; // Terminates due to underflow.
j = j.wrapping_sub(10_u32); // Wraps around by explicitly asking for it.
sus::Option<u32> r = j.checked_sub(10_u32); // Tells you if it underflowed by returning Option.
Oh, and that is all constexpr.
When I got to checked_sub() I needed an Option type, so I moved on to that. Subspace now
has Option<T> which supports:
- Holding a reference type, as
Option<T&>. No nullable pointer required. - The null pointer optimization
in a more general form, as the
sus::NeverValueFieldconcept. - Safe defaults. Terminates if
unwrap()is called when there’s nothing inside. If moved-from, the Option contains nothing, instead of containing an object in a moved-from state. - Can be used in a
switchstatement, and should C++ gaininspectit will work there too. - Methods to transform the contained value in a safe way, producing a new
Optionwith the transformed value.
sus::Option<i32> o = sus::some(2_i32);
sus::Option<i32> n = sus::none();
// Protects against UB.
sus::move(n).unwrap(); // Terminates since there's no value inside.
pass_along(sus::move(o));
o.unwrap(); // Terminates as the value was moved away.
// The null pointer optimization means no extra boolean flag.
static_assert(sizeof(sus::Option<i32&>) == sizeof(i32*));
// The NeverValueField optimization means no extra boolean flag for
// other types as well.
static_assert(sizeof(sus::Option<sus::Vec<i32>>) == sizeof(sus::Vec<i32>));
Oh, and this is all constexpr too. However due to limitations of unions and standard layout types in a constexpr context, reading the current state from an Option is not constexpr. This could point toward a future change in the C++ standard that would have a clear benefit. I will write a future blog post about the NeverValueField optimization and the limitations here.
The Option type plays along with Result in all the same ways as in Rust, and they each play along with Iterators in the same way too.
auto v = Vec<Option<i32>>();
v.push(sus::some(1));
v.push(sus::some(2));
Option<CollectSum> o = sus::move(v).into_iter().collect<Option<CollectSum>>();
// If `v` contained an empty option, `o` will be an empty option.
// Otherwise, `v` contains CollectSum, which is a `FromIterator` type and
// has itself collected all the values in the vector.
// The same works with collecting `Result`s, where you get back a `Result` with
// the collected answer, or the first error found.
auto v = Vec<Result<i32, ErrCode>>();
Result<CollectSum, ErrCode> r = sus::move(v).into_iter().collect<Result<CollectSum, ErrCode>>();
If only C++ could infer the type parameter for collect(). Maybe a future C++ standard
could address this.
But yes, Subspace has Iterators too. Not pairs of pointers like the C++ standard library. Composable Iterator objects which present a single object, and thus a single lifetime, to the compiler. And they work with C++ ranged for loops. Using them compiles twice as fast as C++20 ranges, and doesn’t consume exponential stack space: subspace vs ranges.
auto v = sus::Vec<i32>();
v.push(1);
v.push(3);
v.push(5);
auto count = v.iter().filter([](const i32& i) { return i >= 3; }).count();
// `count` will be `2_usize`.
auto sum = 0_i32;
for (const i32& i: v) {
sum += i;
}
// `sum` will be `9_i32` (from 1 + 3 + 5).
The use of sus::move() above doesn’t stand out, but even it provides safer
defaults to std::move() by rejecting a const input. With std::move()
you just get a copy instead with no visible indication that it occurred. And along
with the principle of building on its own types, I’ve used sus::move() throughout
the library implementation, showing it was not a problem for template code.
And there’s unsafe, but we can’t add keywords. So instead there’s unsafe_fn,
a marker type passed to functions or methods that may introduce UB if you hold
them wrong. This gives the means to go below the safe API where you need to,
in super narrowly scoped ways, and without having to write
whole new data structures
to avoid libc++ hardening.
auto v = sus::Option<u32>();
sus::move(v).unwrap_unchecked(unsafe_fn); // Oops, UB! But you asked for it.
The library introduces the concept of trivially relocatable in a type-safe way without changing the language.
Clang has provided a [[clang:trivial_abi]]
attribute for a few
years, which has recently been extended to apply to a new __is_trivially_relocatable
builtin. This allows libc++ to
perform trivial relocation for annotated types. However the attribute can not be used
on template classes where the template parameters would affect the trivial-relocatability
of the type, such as if any type parameters define a value inside the class.
The subspace library provides the concepts
relocate_one_by_memcpy
and
relocate_array_by_memcpy
which determine if a type is trivially relocatable. The determination is made based
on clang’s __is_trivially_relocatable if possible. But it also allows a template
class to opt into being trivially relocatable based on its template parameters,
through
sus_class_maybe_trivially_relocatable_types()
or similar hooks.
The result is that sus::Option<i32> is treated as trivially relocatable within the
subspace library, and can be done so by user code as well by checking relocate_one_by_memcpy<T>.
This is possible only because sus::Option<NotRelocatableType> can be differentiated and
will not be treated as trivially relocatable.
Where does Subspace go next
There’s a lot more to do in the library, but it’s reached a point where
- The core pieces are there from which to build the rest, and they work.
- The most risky looking things have been able to be ported over, and I am no longer worried that this part of the experiment will fail.
But new vocabulary types have a huge cost. Even if this library provides a means to avoid all the sharp edges of the C++ standard library, it would represent a large fracture in the C++ ecosystem. I believe it needs to provide more value than just its APIs to be worth adopting it outside of specialized scenarios.
One of the most interesting things about porting the Rust standard library APIs into C++ is that we know that those APIs, and use of those APIs, will pass a borrow checker. And to bring safety to C++ needs more than APIs without UB, it needs memory safety.
But we have already established that borrow checking is not feasible from within the C++ type system. But I believe that it is feasible, even for C++, inside a compiler.
But it means introducing more restrictions to C++ code
than just lifetimes on pointers and exclusive access through mutable pointers. In Rust,
const is transitive through references, and this is core to its ability to determine exclusive
mutability. So a C++ borrow checker will need to enforce new rules on const as well.
At this time, such a large lift would not be feasible in any production C++ compiler, and it could actually be a poor choice as it would restrict the use of it to that single compiler. So, like cfront and cppfront, I believe it’s time to write a compiler. But instead of producing code, it need only produce a yes or a no-with-errors as its outputs.
The Rust team built their first borrow checker on Rust’s HIR, something akin to the Clang AST. This ended up complicating their implementation and restricting the rules they were able to enforce. In my contributions to Crubit’s lifetime analysis I have also seen the difficulty of building on top of the AST. The full complexity of C++ has to be dealt with all over your tool. Rust solved this problem by introducing MIR, a mid-level representation of the language that reduces the full language down to a small set of instructions. This enabled a new evolution in their borrow checker, and new compiler optimizations. For now, I am mostly interested in the former.
A recent brainstormy conversation with my colleague @veluca93
made me believe that a MIR for C++ is also possible. So my path to writing a borrow checker
is going to start with producing a MIR for C++, denoted CIR. Some quick iteration with
@veluca93 has produced
a simple syntax,
which is still in flux, but is something like this for constructing and destructing a class S.
fn f@0() -> void {
let _1: S
let _2: *S
bb0: {
_2 = &_1;
call S::S(_2)
call S::~S(_2)
return
}
}
It will need to grow to support some parts of the language, like async. But it’s a clear simplification over the clang AST and, as Rust has shown, along with lifetime annotations, it can have everything we need to write a borrow checker.
The future
This is a wild experiment, but if successful it would give us a world where we can write C++ with memory safety, by running a borrow checker against it.
It won’t fix existing code, but it won’t break existing code either, and it doesn’t require complicated FFI with extra rules at the boundary between safe and unsafe C++. You simply do or do not choose to borrow check your code.
And it will provide the basic building blocks in a standard library to write new safe C++, and incrementally move existing C++ into a safe world.
Other recent work
Cpp2
I see this work as being very complimentary to Cpp2, introduced at CppCon22. Herb presented this graph of CVE root causes:
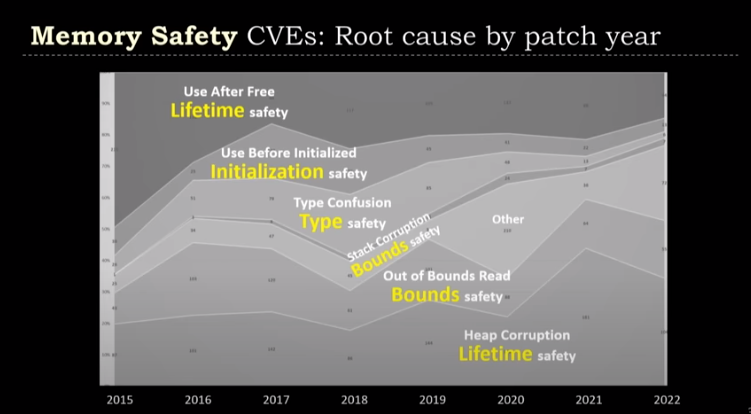
- Lifetime safety is ~50% of CVEs.
- Bounds safety is ~40% of CVEs.
- However, I believe Herb mixed in all integer overflow with bounds safety based on his claim that it only matters if it causes an out of bounds issue. Nonetheless, signed integer overflow is UB which produces security bugs with or without bounds overflow, so some part of this number should be counted separately as integer overflow in my opinion.
- Initialization safety is ~5% of CVEs.
- Type safety is ~3% of CVEs.
The Cpp2 syntax provides new answers for things that need a code-generating compiler: initialization safety and type safety. These address ~8% of CVEs by the previous graph.
The syntax also addresses bounds safety in a way that needs a compiler intervention, by banning pointer arithmetic. This is very similar to the C++ Buffer Hardening proposal for clang, though without the opt-in/opt-out semantics other than dropping down to a standard C++ syntax function. It also introduced bounds checks on containers that crash, which is basically the “c++ safe mode” without your standard library opting in, and without an API choice to crash or return an Option. Together, these address some part of the bounds safety CVEs, though it’s not clear how much.
If successful, Subspace would address bounds safety on containers a richer way, but would also rely on a compiler like Cpp2 or C++ Buffer Hardening to deal with pointer arithmetic.
Subspace will also address lifetime safety which is the root cause of the other ~50% of CVEs.
Not mentioned at all in the analysis presented at CppCon22 is Undefined Behaviour. Since UB does lead to security vulnerabilities, these bugs must be getting grouped into other categories, like type safety with unions, or being omitted. Nonetheless, Subspace will address the wide access to UB that is present in the C++ standard library.
C++ Buffer Hardening
Clang recently began development on a “C++ Safe Buffers” proposal that would allow for banning pointer arithmetic outside of clear opt-in scenarios, and allows for incremental adoption of the restriction across an existing codebase.
The user documentation is still under review at this time, though implementation has already begun.
I gave a talk about this at a Chrome-hosted memory safety summit in November, from which you can see the slides and speaker notes.
This work, like Cpp2, is very complimentary to Subspace. Functions that perform unchecked
pointer arithmetic today would use the Subspace unsafe_fn marker type as a function parameter
to denote the jump to unsafety. The C++ Safe Buffers warning brings this into the compiler with a
[[clang::unsafe_buffer_usage]] annotation. The downside of this approach comes from current
limitations of C++:
- It is non-standard so it’s only available in a single compiler.
- It requires using #pragmas to inform the compiler that a call-site can call an annotated function. In the future, I would love to see C++ adopt the ability to apply attributes to blocks of code other than functions in order to remove the requirement of #pragmas for static analysis.
Swift exclusivity
Swift recently announced that they will begin enforcing exclusive mutability in the language in order to guarantee their memory safety goals.
This is a terrific step and further demonstrates the importance of exclusive mutability. It also gives further evidence, alongside Rust, that a production systems programming language can require it, and can check for it at compile time. This does look like the future of systems development.
4bae52616d8070a7c137d53861002ad822787e8a