tl;dr We are going to see how Subspace types allow a zero-cost transition from native pointers to bounded view types, which enable spatial memory safety, and that can’t be achieved with the standard library types.
Long ago, C and C++ programmers passed around pointers to arrays, hopefully with a size to indicate
how large the array was in order to avoid reading/writing out of bounds, though frequently not. This
is still a common pattern, though “modern C++” has provided tools to eliminate this class of memory
safety bug, through the use of “view” types. These are types like std::string_view or std::span
in the standard library. Unfortunately, these types don’t actually check for using memory out of
bounds in the C++ standard.
Much has been written about the memory unsafety of lack of bounds checking, and we (as in the software industry) have known ways to solve this simple issue for decades now.
- Here’s an article from 1996 (almost 30 years ago) proposing a bounds-checked structure for interacting with OLE.
- Here’s a NIST paper titled “C++ in Safety Critical Systems” from 1995 which states “Class libraries that provide smart (safe) pointers and array bounds checking should be used.”
In 2022, The Clang/Libc++ project accepted the C++ Buffer Hardening proposal that makes it possible to enable hardening checks inside these standard library types with bounds - though it requires you to compile the standard library yourself with the option enabled. The compiled copy of the standard library that shipped with your operating system likely doesn’t have this enabled. At least your web browser may have this enabled (Chrome has since Q1 2023, but I don’t know about any other browser, Chromium-derived or not).
The same proposal introduces the -Wunsafe-buffer-usage warning in Clang
which you can enable to ban pointer arithmetic. This is very useful to help a
project convert all their native array pointers into view types, which pair a size
with the pointer through the type system. See, the problem is that even if you enable bounds
checking in std::span and std::string_view, the majority of C++ code really doesn’t use those
types. The large C++ codebases that power modern technology are still full of pointers to arrays.
So this warning gives a mechanism to start migrating away from pointers,
and then prevent backsliding, working toward banning pointer arithmetic entirely outside of a
few exceptional types.
Performance implications
Introducing memory safety into C++ codebases always comes with some performance degradation, because there’s little you can check at compile time. So it means checking for bad program states when the program is running. These performance changes are not the kind you as a user will see or feel, but the kind that shows up on benchmarks and that software teams then have many discussions about. And these often end up blocking meaningful improvements to the safety of users and their data.
In bounds checking, the compiler can see the values involved in the comparisons, as they come from constants or other values related to the array. For instance when iterating through a span, stopping before the span’s length, the compiler can see that every index into the span is less than its length fairly trivially. This usually means the compiler removes the bounds checks. So no runtime overhead, yay!
But there’s another type of overhead that comes not from the bounds checks in view types like
std::span or std::string_view, but from the change to using those types at all.
Here’s a commit that converts a bunch of functions to use base::StringPiece, the Chromium string
view type which is much like std::string_view:
Make histogram functions take base::StringPiece.
The functions were previously overloaded to take const std::string& or const char*. The
const char* overload presumes that:
- the string being passed in is null-terminated, and
- the function should be consuming the full string up to the null character.
These assumptions are easily wrong when working with view types that encode a bounded view of an
array. Calling these functions requires converting that bounded string view into a std::string
which involves generating a constructor, and quite possibly a heap allocation. But
many callers instead convert their bounded string view into a const char* through .data()
instead, which is a bug. Props to @davidben for noticing this common
anti-pattern in Chromium and working to fix the many places it occurs.
So it appears at first glance to be a win to change these functions to take a string view type, in
this case base::StringPiece. For callers with a std::string, it will copy the pointer and length
into the base::StringPiece. For callers with a bounded string view type, they don’t need to throw
away the bounds or allocate on the heap. Yet this created a pretty large binary size regression for
doing almost nothing, and trying to eliminate heap allocations.
Chromium is an interesting test bed because it is an enormous codebase. So when you make a small
change, it can easily be amplified immensely. In this case, we discovered that all those calls to a
base::StringPiece constructor grow the binary by 36KB. For unknown reasons, the
base::StringPiece constructor gets inlined, while the std::string_view constructor does not, so
you get less binary size growth with that type (and we’ll look at marking base::StringPiece with a
noinline attribute).
In Chromium, when a change impacts performance, we can often just look for where binary size grew
to track down where the regression lies. So we’ve seen binary size growth correlate well with
performance loss. In this case we see strictly more codegen at each call site, which can certainly
become visible at scale in performance testing.
So this also suggests a performance degradation by moving from pointers to a bounded view type.
And herein lies the problem. A project may successfully flip libc++ hardening on for their
std::span types without seeing much of a performance impact, because the majority of bounds
checks are elided. But then as they convert more pointers to std::span to increase their
coverage of bounds safety, the use of std::span may introduce a different kind of performance
(and binary size) regression.
Here’s a code example (in compiler explorer):
#include <stddef.h>
#include <vector>
#include <span>
#include <fmt/core.h>
void take_vector(const std::vector<int>& v) {
fmt::println("{}", v[0]);
}
void take_pointer(const int* p, size_t s) {
if (0 >= s) abort();
fmt::println("{}", p[0]);
}
void take_span(std::span<const int> s) {
fmt::println("{}", s[0]);
}
int main() {
std::vector<int> a = {1, 2, 3, 4, 5, 6, 7};
take_vector(a);
take_pointer(a.data(), a.size());
take_span(a);
}
We will look at the resulting code gen unoptimized, to keep things simple. But the above commit demonstrated the same principle under optimizations.
Here’s the call to take_vector():
lea rax, [rbp-80]
mov rdi, rax
call take_vector(std::vector<int, std::allocator<int> > const&)
This is three instructions. Grab the pointer, store it, and call the function. Nice.
Here’s the call to take_pointer():
lea rax, [rbp-80]
mov rdi, rax
call std::vector<int, std::allocator<int> >::size() const
mov rbx, rax
lea rax, [rbp-80]
mov rdi, rax
call std::vector<int, std::allocator<int> >::data()
mov rsi, rbx
mov rdi, rax
call take_pointer(int const*, unsigned long)
That’s a lot more instructions, as there’s two function calls first. Then store the two values and
make the call. This is why we had a const std::string& overload for those functions. In the case
the caller already had a decomposed pointer/length, this would result in just something like the
last three instructions, which is as good as take_vector().
And here’s the call to take_span():
lea rdx, [rbp-80]
lea rax, [rbp-48]
mov rsi, rdx
mov rdi, rax
call std::span<int const, 18446744073709551615ul>::span<std::vector<int, std::allocator<int> >&>(std::vector<int, std::allocator<int> >&)
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-40]
mov rdi, rdx
mov rsi, rax
call take_span(std::span<int const, 18446744073709551615ul>)
Oof, that’s a lot more instructions than take_vector(). Calling this function with a vector has
changed three instructions into ten, and that’s without inlining the std::span constructor.
I guess it’s easy to see why the binary size changes when we start to receive std::span in
function parameters instead of a reference to the owning container.
What if we had a pointer and length already, but we wanted to call take_span() instead of
take_pointer(), is that any better? Something like this:
auto p = a.data();
auto s = a.size();
take_span({p, s});
That turns into the following when calling take_span():
mov rdx, QWORD PTR [rbp-32]
mov rcx, QWORD PTR [rbp-24]
lea rax, [rbp-64]
mov rsi, rcx
mov rdi, rax
call std::span<int const, 18446744073709551615ul>::span<int*>(int*, unsigned long)
mov rdx, QWORD PTR [rbp-64]
mov rax, QWORD PTR [rbp-56]
mov rdi, rdx
mov rsi, rax
call take_span(std::span<int const, 18446744073709551615ul>)
It’s one more instruction to call take_span() when you have a pointer/length pair than to call
take_pointer() when you have a std::span!
Conversions can be costly for codegen in C++, which is why they should pretty much
always be explicit,
even for (if not especially for) these small vocabulary types. I go further to take the point of
view that conversion constructors are harmful to understanding what code you are generating, even
if explicit, and static constructor methods are better.
But anyway, what do we do? I want to stop out-of-bounds bugs in C++ code from constantly being exploited. I want to stop the people who want to steal all of your private data. Silent and persistent compromise, which allows theft of your past, present and future data, is not as rare or as difficult as it should be, and that is due in part to memory unsafety bugs like out of bounds memory accesses.
Making the conversion free
While walking my puppy today, it occurred to me that it
is possible to have that conversion to std::vectorfrom std::span be free; to generate the
same code when calling take_span() as when calling take_vector(). Well, no okay it’s not
possible with the standard library. But it is possible with the Subspace library.
Let’s expand our example a bit (in compiler explorer):
void take_vector(const std::vector<int>& v) {
fmt::println("{}", v[0]);
}
void take_pointer(const int* p, size_t s) {
if (0 >= s) abort();
fmt::println("{}", p[0]);
}
void take_span(std::span<const int> s) {
fmt::println("{}", s[0]);
}
void take_span_ref(const std::span<const int>& s) {
fmt::println("{}", s[0]);
}
void take_vec(const sus::Vec<int>& v) {
fmt::println("{}", v[0]);
}
void take_slice(sus::Slice<int> s) {
fmt::println("{}", s[0]);
}
void take_slice_ref(const sus::Slice<int>& s) {
fmt::println("{}", s[0]);
}
int main() {
std::vector<int> a = {1, 2, 3, 4, 5, 6, 7};
take_vector(a);
take_pointer(a.data(), a.size());
take_span(a);
take_span_ref(a);
auto b = sus::Vec<int>::with_values(1, 2, 3, 4, 5, 6, 7);
take_vec(b);
take_slice(b);
take_slice_ref(b);
}
We’ve added a call to take_span_ref() which receives a const std::span&. Unsurprisingly this
does not improve anything, here is the codegen for that call:
lea rdx,[rbp-0x60]
lea rax,[rbp-0x30]
mov rsi,rdx
mov rdi,rax
call 404b2e <std::span<int const, 18446744073709551615ul>::span<std::vector<int, std::allocator<int> >&>(std::vector<int, std::allocator<int> >&)>
lea rax,[rbp-0x30]
mov rdi,rax
call 403acf <take_span_ref(std::span<int const, 18446744073709551615ul> const&)>
We have to construct a std::span from the std::vector in order to give a reference to it in the
function call, so this comes out at eight instructions, without the std::span constructor being
inlined.
Now let’s look at the Subspace types.
First, receiving a const sus::Vec& looks the same as const std::vector&, which isn’t surprising:
lea rax,[rbp-0x70]
mov rdi,rax
call 403c75 <take_vec(sus::Vec<int> const&)>
We grab the pointer, store it and call the function, for three instructions.
And receiving a sus::Slice looks much like receiving a std::span:
lea rax,[rbp-0x70]
mov rdi,rax
call 404bf0 <sus::Vec<int>::operator sus::Slice<int>&() &>
mov rdx,QWORD PTR [rax]
mov rax,QWORD PTR [rax+0x8]
mov rdi,rdx
mov rsi,rax
call 403e1b <take_slice(sus::Slice<int>)>
We construct a sus::Slice and then pass that by value to take_slice(). This actually comes in
two instructions shorter than the call to take_span(), but it’s still way more codegen than
passing the const sus::Vec& directly.
But lastly, we have the call to take_slice_ref(), which now differs significantly from the
equivalent take_span_ref() with the standard library types:
lea rax,[rbp-0x70]
mov rdi,rax
call 404bf0 <sus::Vec<int>::operator sus::Slice<int>&() &>
mov rdi,rax
call 403fd1 <take_slice_ref(sus::Slice<int> const&)>
Now we’re down to five instructions. We call the conversion operator to sus::Slice&, which returns
a pointer that we store, and then call take_slice_ref() with it.
But why is this operator returning a pointer, instead of a sus::Slice by value? The trick here
is that sus::Vec is implemented by holding a sus::SliceMut inside it, which holds a
sus::Slice inside it1, which is where the pointer/length pair is finally found. This means that
Vec can convert to a SliceMut and Slice without any constructor being invoked.
With optimizations
Ok let’s turn some optimizations back on and see what we get.
Calling take_vector(const std::vector&) grabs the pointer and invokes call:
lea rdi,[rsp+0x10]
call 4035e6 <take_vector(std::vector<int, std::allocator<int> > const&)>
Calling take_span(std::span) inlined the std::span constructor for us, which sets its two data
members and then invokes call:
mov rdi,rbx
mov esi,0x7
call 403719 <take_span(std::span<int const, 18446744073709551615ul>)>
Calling take_span_ref(const std::span&) is worse, as it constructs a std::span inline, then has
to take its address. No doubt that’s where we get the guidance from to pass it by value:
mov QWORD PTR [rsp+0x30],rbx
mov QWORD PTR [rsp+0x38],0x7
lea rdi,[rsp+0x30]
call 4037ab <take_span_ref(std::span<int const, 18446744073709551615ul> const&)>
Calling take_vec(const sus::Vec&) looks similar to receiving const std::vector&, as it grabs
the pointer and invokes call:
mov rdi,rsp
call 403840 <take_vec(sus::Vec<int> const&)>
Calling take_slice(sus::Slice) looks similar to receiving std::span, inlining the construction
of a sus::Slice, then passing it by value:
mov rdi,QWORD PTR [rsp]
mov rsi,QWORD PTR [rsp+0x8]
call 4038e3 <take_slice(sus::Slice<int>)>
Calling take_slice_ref(const sus::Slice&) is where things differ in a meaningful way:
mov rdi,rsp
call 403981 <take_slice_ref(sus::Slice<int> const&)>
The call to take_slice_ref() uses the exact same instructions as the call to take_vec(). This
means we are able to use a bounded view type (sus::Slice) as a function parameter without taking
a binary size and performance cost at every function call that moves from an owning type to a view
type. And that’s something that we can’t do with the standard library types.
Benchmarks
Here’s all of the options in Quickbench, compiled with GCC.
We call the function once per iteration, and the function does a single indexing operation into
each slice. The const sus::Slice<T>& option comes out on top, exactly equal with
const sus::Vec<T>& which aligns with what we see in the assembly code above.
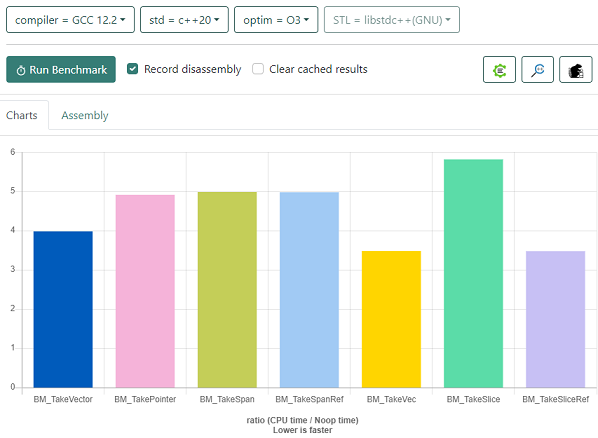
Note: We don’t call the function a bunch of times, like we do with Clang, because GCC ends up
setting up the stack for the function call once and then just doing call successively, which is
not representative of the whole function call operation.
And here’s the same thing in Quickbench, but compiled with Clang 15. We call the function 21 times per iteration to avoid Clang mostly measuring the benchmark harness itself, and the function again does a single indexing operation into each slice.
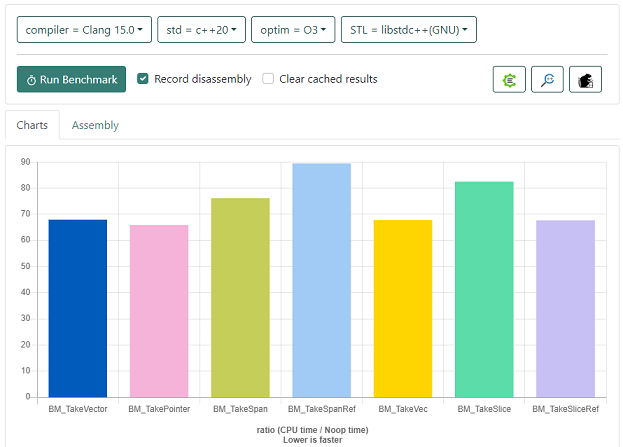
Benchmarks Result
Across both compilers, we can see that receiving a const sus::Slice& parameter from an owning
vector argument is as efficient as const sus::Vec& or const std::vector&, while all three are
more efficient than receiving std::span.
Library choices that got us here
There’s a couple differences in Subspace that work together to get us to this point.
First, the nesting strategy of Vec{SliceMut{Slice{T*}}}. This is not done with inheritance as you
might first expect. That would allow a const Vec& to be used as a const Slice&, but it would
also allow a const Vec& to be used as a const SliceMut&. A SliceMut provides a mutable view
of the array, meaning this would be a backdoor through const Vec& to trivially mutate the data
inside it. So instead Vec and SliceMut provide operators to convert to references of their
nested types which provide the library control over when the types should be allowed to convert.
This ended up very similar in implementation to the Deref trait in Rust, which is what inspired me to try this
at all.
Secondly, the splitting of Slice and SliceMut into different types. Originally I had designed
Slice to specify the const-ness of its view through the template parameter, like you would with
std::span. That is Slice<const T> was a const view and Slice<T> was mutable. This made hiding
methods that should not exist on a const view much more annoying, as they would need to each grow
a requires(!std::is_const_v<T>). For programmers reading the API these are purely noise when you
have a Slice<const T>, making the API harder to read and use and hack on. I think the standard
library type gets away with this by putting almost no methods on std::span, as it has a
methodology of providing free functions (like std::find()) instead. This type-splitting means that
it’s much simpler to have a const SliceMut<T>& still implement a mutable view of the array.
A const sus::Slice<T> would have been more deceptive.
Since the standard library differs on both of these, I don’t think the same strategy would work as well in that environment, even if standard was willing to break backward compatibility to get this performance win.
Thanks
Thank you @noncombatant for the excellent proofreading and suggestions for this post.
-
For
Vecto convert toSliceMutin this way, it must hold aSliceMutinside forVecto return a reference to theSliceMut. Likewise,SliceMutcan convert to aSlicesince gainingconstis a valid operation, though not the inverse. ThusSliceMutcontains aSliceand can convert toSliceby returning a reference to it. ↩